

O web scraping é muito importante para coletar dados estratégicos. Ele ajuda empresas a tomar decisões melhores em um mercado competitivo. Essa técnica extrai informações de vários sites automaticamente, economizando tempo e aumentando a precisão.
Esse artigo vai mostrar como usar web scraping para coletar dados estratégicos. Também vamos ver como isso pode melhorar suas análises. Vamos discutir questões éticas e legais da coleta de dados, para que você saiba como agir de forma correta.
Principais Pontos
- O web scraping permite uma coleta de dados significativamente mais rápida do que métodos manuais.
- A precisão dos bots utilizados é superior à dos humanos, resultando em menos erros.
- Ferramentas populares de marketing utilizam técnicas de web scraping para extrair dados relevantes.
- É essencial respeitar as limitações descritas nos arquivos robots.txt para evitar problemas legais.
- O uso de cookies e proxies pode ajudar a evitar bloqueios enquanto se coleta dados da web.
O que é Web Scraping?
Web scraping é uma técnica que ajuda a coletar dados de forma automática de sites. Ela extrai informações importantes para melhorar estratégias empresariais. Com a tecnologia avançando, entender o web scraping é crucial para ter vantagem no mercado.
Definição e Importância
A definição de web scraping é simples: é a extração de dados online. Esses dados são muito valiosos, chamados de “o novo petróleo”. Empresas que usam bem esses dados melhoram muito suas vendas e satisfação do cliente.
Principais Ferramentas Utilizadas
Existem várias ferramentas de scraping que ajudam muito. Algumas das mais usadas são:
- Beautiful Soup
- Scrapy
- Webscraper.io
Essas ferramentas tornam a coleta de dados mais fácil. São muito usadas por profissionais de marketing digital e inteligência de mercado.
Aplicações Práticas no Dia a Dia
O web scraping tem muitas aplicações. Por exemplo, em e-commerce, ajuda a monitorar preços. Isso permite ajustes nas estratégias de venda. Além disso, ajuda a analisar tendências e comportamentos do consumidor, usando ferramentas de scraping.
Como Funciona o Processo de Web Scraping?
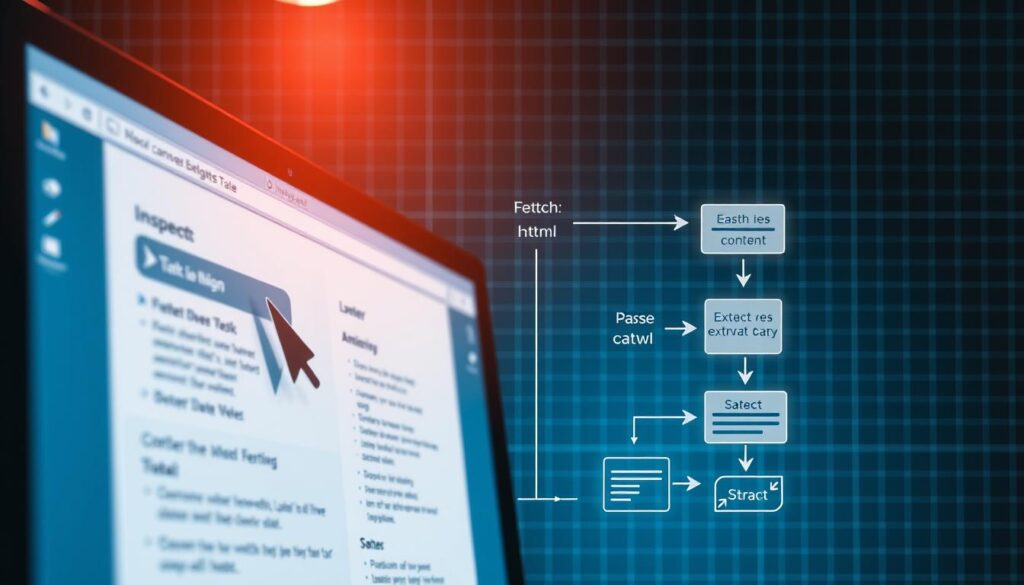
O web scraping é a arte de pegar dados de sites. É essencial entender como funciona para obter informações precisas. Vamos falar sobre estruturas de dados, métodos de coleta e restrições.
Estruturas de Dados na Web
As informações na web estão em HTML. Isso ajuda as ferramentas de scraping a pegar dados facilmente. Usar robôs para coleta traz dados mais confiáveis e atualizados.
Diferentes Métodos de Coleta
Existem vários métodos para coletar dados. Alguns são simples, outros desafiadores. Bibliotecas como Beautiful Soup são muito eficazes. A automação melhora a eficiência e libera funcionários para tarefas complexas.
Protocolos de Acesso e Restrições
É importante seguir os protocolos de acesso dos sites. Isso evita problemas legais. A LGPD exige autorização para dados pessoais, mas não para empresas. A coleta automática, feita de forma ética, é legal e útil.
Passos Iniciais para Começar
Iniciar no web scraping pode parecer difícil, mas é simples com os passos certos. É importante escolher as ferramentas certas e configurar um ambiente de trabalho. Também é crucial buscar fontes de dados confiáveis para obter informações relevantes e atuais.
Escolhendo as Ferramentas Certas
Escolher as ferramentas certas é o primeiro passo para um projeto de sucesso. Python é uma boa escolha por sua versatilidade e grande biblioteca. Para quem prefere JavaScript, o Puppeteer é ótimo, especialmente para manipular DOM.
Para instalar o Puppeteer, basta usar o comando `npm install –save puppeteer. Usar o Node.js versão 12.18.3 com npm 6.14.6 ajuda a criar um ambiente forte para o scraping.
Configurando o Ambiente de Trabalho
Depois de escolher as ferramentas, é hora de configurar o ambiente. Iniciar o npm com `npm init` cria um arquivo package.json para gerenciar dependências. Com arquivos como browser.js e pageScraper.js, faço a instalação das bibliotecas necessárias.
O Puppeteer permite criar scripts eficientes para coletar dados.
Buscando Fontes de Dados Confiáveis
Encontrar fontes de dados confiáveis é essencial para a qualidade das informações. Plataformas de teste, como books.toscrape.com, são seguras para praticar. Durante o scraping, uso o método `page.$$eval()` para coletar links de livros “In Stock”.
Essa seleção de fontes confiáveis faz com que os dados coletados sejam relevantes e atualizados.
Identificação de Dados Estratégicos
Na era do Big Data, identificar dados estratégicos é essencial para empresas que querem se destacar. Esses dados são informações cruciais que ajudam a tomar decisões de negócios. Eles são fundamentais para criar estratégias eficazes.
Com tantas informações disponíveis, saber de onde vêm esses dados é crucial. Além disso, analisar a concorrência é uma etapa importante.
O Que São Dados Estratégicos?
Dados estratégicos são informações que influenciam as decisões da empresa. Eles podem ser sobre o comportamento do consumidor, tendências de mercado e o desempenho da concorrência. Entender esses dados ajuda a direcionar melhor as estratégias comerciais e de marketing.
Como Identificar Fontes Relevantes
É essencial encontrar fontes de dados confiáveis. Isso pode ser feito através de pesquisas de mercado, bancos de dados de clientes e análises de dados. Ferramentas como Google Trends e APIs de busca são úteis para coletar dados atuais do mercado.
Além disso, monitorar redes sociais pode dar insights valiosos. Isso, desde que o público-alvo esteja ativo nessas plataformas.
Analisando a Concorrência
Analizar a concorrência ajuda a entender como outras empresas operam. Isso inclui como elas posicionam seus produtos e interagem com os consumidores. Comparar esses dados pode revelar padrões para melhorar a própria performance.
Ferramentas de CRM podem integrar esses dados de forma eficiente. Isso permite uma análise mais profunda da jornada do cliente. E ajuda a tomar decisões mais informadas.
Extrair Dados de Websites
Coletar informações valiosas de websites é essencial. Primeiro, é preciso estruturar queries para direcionar as ferramentas de scraping. Assim, os dados são extraídos de forma eficiente e organizada.
Estruturação de Queries de Extração
Definir queries precisas é crucial para coletar dados com eficácia. Usar localizadores, como seletores CSS e XPath, ajuda a identificar rapidamente os elementos desejados. Porém, mudanças na estrutura HTML podem afetar a extração. Por isso, é importante planejar com cuidado.
Usando Python para Web Scraping
Python é uma das melhores linguagens para web scraping. Bibliotecas como Beautiful Soup e Scrapy tornam a programação mais simples. Elas permitem navegar e manipular HTML, facilitando a extração de dados. Com Python, posso automatizar tarefas, economizando tempo.
Testando a Extração de Dados
Depois de configurar, é hora de testar a extração. Essa etapa é crucial para garantir a precisão dos dados. Testes ajudam a identificar falhas e otimizar o processo. Eles também evitam sobrecarregar servidores com muitas solicitações.
Lidar com Desafios Comuns
Enfrentar desafios no web scraping é comum. Os bloqueios de sites são mais frequentes por causa das medidas de segurança. É crucial saber lidar com esses problemas para que a coleta de dados continue bem-sucedida.
Bloqueios e Proteções em Sites
Os bloqueios de sites são um grande obstáculo. Plataformas usam técnicas como limitação de taxa e CAPTCHAs para proteger dados. Reconhecer esses bloqueios cedo ajuda a ajustar as estratégias, usando scrapers que imitam o comportamento humano ou mudam de IP.
Como Evitar Banimentos
Evitar banimentos é um grande desafio. Enviar requisições com intervalos e seguir os termos de uso são práticas úteis. Usar proxies também ajuda, pois espalha as solicitações por diferentes IPs, diminuindo o risco de bloqueios.
Tratamento de Erros de Coleta
Tratar erros de coleta é essencial. É importante ter um sistema que identifique falhas automaticamente, como erros de conexão. Ajustar o scraper para lidar com esses erros melhora a eficiência da coleta.
Armazenamento e Análise de Dados

Depois de coletar dados, é crucial armazená-los de forma eficiente. Isso garante que as informações sejam fáceis de acessar e usar. O armazenamento de dados deve ser feito em formatos adequados, como o banco de dados SQLite. Esse formato facilita muito a manipulação e recuperação das informações.
Formatos Comuns de Armazenamento
Existem vários formatos comuns para armazenar dados:
- CSV – ótimo para dados estruturados e fáceis de manipular.
- Banco de dados relacionais, como SQLite – perfeito para acessar rapidamente grandes volumes de dados.
- JSON – útil para dados hierárquicos e interações com APIs.
Ferramentas de Análise de Dados
Com os dados armazenados, a análise de dados é o próximo passo. Ferramentas como Google Data Studio e Tableau são muito eficazes. Elas transformam dados brutos em insights valiosos. Essas ferramentas ajudam a criar gráficos dinâmicos, tornando a visualização e compreensão das tendências mais simples.
Criando Relatórios para Acompanhamento
Para monitorar os resultados de forma eficiente, é crucial criar relatórios. Relatórios bem feitos ajudam a acompanhar as métricas-chave. Eles oferecem uma visão clara dos dados coletados. É importante considerar:
- Periodicidade do relatório – semanal, mensal ou trimestral.
- Visualizações gráficas – para tornar a leitura e interpretação mais fácil.
- Dados contextuais – para fornecer comparações históricas e previsões futuras.
Uma boa prática de armazenamento de dados, análise de dados e criação de relatórios melhora muito a gestão das informações. Isso também ajuda na tomada de decisões estratégicas.
Éticas e Legislação em Web Scraping
É crucial fazer web scraping com responsabilidade para evitar problemas legais e éticos. É essencial entender as leis, como a LGPD no Brasil e o GDPR na UE. Assim, pode-se usar essa técnica de forma eficaz e ética.
O web scraping pode ser muito útil. Mas, sua utilização deve seguir boas práticas de coleta.
Leis que Regem o Uso de Dados
As leis sobre dados pessoais são rigorosas para proteger a privacidade. Empresas podem enfrentar multas pesadas por violar essas leis. No Brasil, os direitos dos consumidores estão em foco, limitando a coleta de dados por web scraping.
Entender essas normas ajuda a evitar problemas legais no futuro.
Boas Práticas na Coleta de Dados
Adotar boas práticas de coleta é essencial para garantir a integridade do processo. É importante respeitar os termos de uso dos sites. Também, evitar sobrecarregar os servidores com muitas solicitações.
Coletar apenas dados públicos segue a ética no web scraping. Além disso, não coletar informações pessoais sem consentimento ajuda a manter uma boa reputação.
Evitar Problemas Legais
Usar indevidamente propriedades intelectuais ou coletar dados sem autorização pode causar problemas legais. Medidas anti-raspagem, como CAPTCHA, podem tornar a situação mais complicada. É importante estar atento aos direitos de uso dos dados e ficar atualizado sobre mudanças na legislação.
Compreender esses aspectos protege meu trabalho. Também ajuda a criar um ambiente de respeito e transparência no web scraping.
Aumentando a Eficiência do Web Scraping

Para ser mais eficiente no web scraping, é essencial usar técnicas de automação. Também é importante focar em fontes de dados confiáveis. Com tantos dados a serem analisados, é crucial otimizar a coleta.
Essas práticas não só economizam tempo. Elas também garantem que os dados coletados sejam relevantes e de qualidade.
Técnicas de Automação
A automação é uma forma eficiente de lidar com grandes volumes de dados. Ferramentas como Scrapy ajudam a criar spiders para coletar informações de forma simultânea. Isso acelera o processo.
Soluções baseadas em nuvem, como Apify, permitem maior escalabilidade. Isso elimina a necessidade de servidores locais. Usar filas de requisições, como RabbitMQ ou Kafka, melhora a gestão das requisições. Isso prioriza as mais importantes, otimizando a coleta.
Priorizando Fontes de Dados
Escolher fontes de dados confiáveis e relevantes aumenta a eficiência. Analisar a concorrência ajuda a entender quais dados são mais valiosos. É crucial monitorar mudanças no HTML para atualizar os scrapers.
Usar IPs e proxies rotativos ajuda a coletar dados sem restrições. Isso garante que as requisições fluam sem interrupções.
Otimizando o Tempo de Coleta
Usar programação assíncrona é uma estratégia eficaz. Ela permite fazer várias requisições ao mesmo tempo. Isso economiza tempo e aumenta a eficiência.
Combinar machine learning com técnicas de scraping melhora a identificação de padrões. Isso permite que o processo se adapte a mudanças nos sites. Essa abordagem melhora a precisão da coleta e reduz a necessidade de intervenção manual.
| Técnica | Vantagens |
|---|---|
| Automação com Scrapy | Processamento rápido de dados em massa |
| Priorizar fontes de dados | Coleta de informações relevantes e atualizadas |
| Programação assíncrona | Aumento na velocidade de coleta |
| Machine Learning | Identificação eficiente de padrões nos dados |
Integração com Outros Sistemas
A integração de sistemas é crucial para maximizar os dados coletados por web scraping. Ela não só aumenta a coleta de informações. Também melhora a análise e visualização dos dados, tornando-os mais valiosos para as empresas.
Usando APIs para Complementar o Scraping
O uso de APIs melhora o scraping, facilitando a troca de informações entre sistemas. As APIs REST permitem acesso estruturado a dados, tornando a extração mais eficiente. Assim, posso conectar dados coletados a outras plataformas e serviços, acelerando a análise.
Integração com Bancos de Dados
Armazenar dados coletados de forma eficiente é essencial. Integrar as informações extraídas com bancos de dados adequados melhora a organização. Através do processo ETL, transformo dados brutos em informações prontas para análise.
Ferramentas de Visualização de Dados
Após coletar e armazenar dados, a visualização é crucial. Ferramentas como Power BI e Tableau transformam dados em gráficos e dashboards interativos. Elas ajudam na interpretação e na tomada de decisões. A visualização eficaz é vital para identificar rapidamente tendências e insights valiosos.
Estudo de Casos Reais

Empresas de vários setores usam web scraping para melhorar suas operações. Essa técnica ajuda a coletar dados importantes. Assim, elas podem monitorar a concorrência e ajustar suas ofertas rapidamente.
Exemplos de Empresas que Usam Web Scraping
E-commerces usam web scraping para ver os preços e descrições dos produtos dos concorrentes. Isso ajuda a ajustar os preços e aumentar as vendas. Empresas financeiras também usam para coletar dados de investimentos, facilitando a tomada de decisões.
Resultados Obtidos com a Técnica
Os resultados de scraping são claros nos relatórios de análise das empresas. Coletar dados ajuda a otimizar campanhas de marketing. Também é essencial para entender a concorrência e adaptar estratégias.
Lições Aprendidas com a Prática
As principais lições são sobre a ética na coleta de dados. É importante respeitar leis como a LGPD. Além disso, o web scraping deve ser parte de uma estratégia geral para entender o consumidor e responder às tendências do mercado.
| Setor | Empresa | Uso do Scraping | Resultados |
|---|---|---|---|
| E-commerce | Amazon | Monitoramento de preços da concorrência | Ajuste de preços em tempo real |
| Financeiro | XP Investimentos | Coleta de dados de mercado | Decisões mais rápidas e informadas |
| Marketing | Análise de palavras-chave | Melhor posicionamento e direcionamento de campanhas | |
| Varejo | Magazine Luiza | Monitoramento de concorrentes | Desenvolvimento de estratégias de resposta |
Futuro do Web Scraping
O futuro do web scraping é cheio de tendências em coleta de dados. Essas tendências buscam melhorar a eficiência e a precisão na coleta de informações. Com a tecnologia avançando, novas experiências inovadoras estão surgindo para tornar a coleta de dados mais eficaz.
Tendências Tecnológicas
A tecnologia está mudando rápido. Diversas tendências em coleta de dados estão moldando o futuro do web scraping. Por exemplo, a inteligência artificial e o machine learning estão sendo usados nas ferramentas de raspagem. Isso permite a análise e extração de dados em maior escala e com maior precisão.
Isso ajuda muito em setores como finanças, saúde e varejo.
A Evolução das Ferramentas de Coleta
As ferramentas de coleta estão evoluindo muito. Plataformas como Webscraper.io e Import.io tornaram o processo mais acessível. Esses recursos oferecem personalização e automação, permitindo que até quem não tem experiência técnica faça scraping de forma eficiente.
Bibliotecas em Python, como BeautifulSoup e Scrapy, estão cada vez mais populares. Elas facilitam muito a extração de dados.
Como Manter a Relevância em Dados Acessíveis
Para manter a relevância em um ambiente de futuro do web scraping, é essencial que as organizações coletem dados em tempo real. É importante monitorar preços em plataformas como Amazon e Ebay. Também é crucial analisar concorrentes.
Isso ajuda a manter vantagem competitiva e oferecer informações atualizadas. Essas informações são essenciais para tomar decisões informadas.
| Tendências Tecnológicas | Evolução das Ferramentas | Importância da Atualização |
|---|---|---|
| Integração de IA e ML | Aumento do uso de plataformas automatizadas | Manutenção da competitividade no mercado |
| Coleta em tempo real | Facilidade de uso para iniciantes | Coleta de dados de múltiplas fontes |
| Expansão no uso de API | Desenvolvimento contínuo de novas bibliotecas | Informações sempre atualizadas e relevantes |
Conclusão e Próximos Passos
Explorar o web scraping revelou a riqueza de informações que ele oferece. Usar bibliotecas como Requests e Beautiful Soup torna a coleta de dados mais fácil. Isso permite criar scripts eficientes em menos de 100 linhas de código.
Essa prática não só extrai dados de várias fontes. Também mostra a importância de seguir normas de acesso e usar dados relevantes para análise.
Recapitulando os Aprendizados
O web scraping é uma ferramenta poderosa para coletar dados valiosos. Isso abre novas oportunidades para empresas de vários setores. É crucial entender como armazenar e analisar esses dados para tomar decisões estratégicas de forma eficiente.
Entender as práticas éticas ao usar essas técnicas aumenta as chances de obter benefícios para o crescimento e inovação empresarial.
Onde Encontrar Recursos Adicionais
Muitos recursos de aprendizado estão disponíveis online. Plataformas como Coursera, Udemy e DataCamp oferecem cursos sobre web scraping e análise de dados. Comunidades como Stack Overflow também são ótimas para troca de experiências e resolver dúvidas.
Essas fontes são muito úteis para novos projetos e desafios de coleta de dados.
Oportunidades no Mercado de Dados
Ter habilidades em web scraping é uma vantagem competitiva no mercado atual. Com a digitalização e a necessidade de decisões baseadas em dados, há muitas oportunidades de mercado. Ferramentas de automação e crawlers são essenciais para aumentar a produtividade e a qualidade dos dados.
Perguntas Frequentes sobre Web Scraping
Se você está começando no mundo do web scraping, pode ter dúvidas. É normal se perguntar sobre legalidade, eficácia e segurança ao coletar dados. Aqui, vamos responder algumas das perguntas mais comuns.
Dúvidas Comuns e Respostas
Uma dúvida comum é sobre o que pode ser coletado sem problemas. É crucial respeitar as regras dos sites e não coletar dados proibidos. Usar proxies ajuda a evitar bloqueios e melhora a coleta de dados.
A raspagem também pode tornar os dados mais precisos. Isso elimina erros e duplicatas, dando insights mais acurados.
Recursos Adicionais para Aprendizagem
Para aprender mais, existem muitos recursos. Blogs, cursos online e fóruns são ótimos para aprender. Eles oferecem um suporte constante, melhorando muito o aprendizado.
Usar ferramentas como BeautifulSoup ou Scrapy também ajuda muito. Elas tornam o processo mais fácil e otimiza os resultados.
Contato para Dúvidas e Suporte
Se ainda tem dúvidas sobre web scraping, entre em contato. Ter um canal de suporte é muito importante. Isso ajuda a construir confiança e eficiência na técnica.
Estou pronto para ajudar e responder qualquer dúvida que você tenha!
FAQ
O que é web scraping?
Quais são as ferramentas de scraping mais populares?
Quais são os benefícios do web scraping?
É legal usar web scraping?
Como posso coletar dados de um site usando Python?
Quais são os principais desafios ao fazer web scraping?
Como armazenar e analisar os dados coletados?
Quais boas práticas devo seguir ao fazer web scraping?
Como integrar web scraping com outros sistemas?
Onde posso encontrar recursos adicionais para aprender sobre web scraping?
Como o futuro do web scraping está sendo moldado?

Especialista em Data-Driven Management e Business Intelligence, reconhecida por sua expertise em transformar dados em decisões estratégicas e vantagem competitiva para empresas. Com uma abordagem analítica e orientada a resultados, ela auxilia organizações na implementação de processos baseados em dados, desde a coleta e tratamento até a modelagem e visualização de informações. Sua atuação abrange desde a definição de KPIs e métricas de desempenho até o uso de inteligência artificial e machine learning para prever tendências e otimizar processos. Ao longo de sua trajetória, Isabel tem ajudado empresas a adotarem uma cultura data-driven, permitindo tomadas de decisão mais assertivas e impulsionando crescimento sustentável e inovação.



